
Etudes des systèmes politiques
Toute civilisation est un organisme social, la plupart du temps, toutes les civilisations se sont construit un système politique qui a pour but de diriger la civilisation dans son entier. (réflexion: peut il y avoir une civilisation anarchiste ?)
Ici, je vais tenter de recenser différents types de gouvernements et de systèmes politiques qui sont ou ont été employés. Ceci permettra de se faire une idée du fonctionnement humain.
Déjà, il faut trouver recenser diverses civilisations et les étudier. Comme point de départ, la page civilisation de wikipedia est il me semble adaptée.
La république romaine
En parlant de recensement de type de systèmes politiques, ce terme vient de la république romaine. A cette époque, on effectuait un recensement tous les 5 ans. On écrivait un album de tous les citoyens papables pour faire partie du Sénat. Et ceci en fonction des capacités censitaires, (financières), d'où le terme recenser.
Lors de chaque recensement on effectuait des cérémonies de purification appelée lustrum d'où le lustre durée de temps égale à 5 ans !

L'étude des institutions politiques de la république romaine est basée en bonne partie sur ce qui vient de la page de wikipedia: institutions de la république romaine.
L'histoire de Rome est très romancée, elle commence par Romulus et Rémus. Romulus défini les contours de Rome à l'aide d'une charrue, il devient donc un tireur de trait, un Rex, qui se traduit par Roi. Puis la légende, raconte que Romulus tue son frère. (involontairement, il avait juste demandé de tuer quiconque entrait dans la zone sacrée... son frère l'a fait, il a été tué.)

Donc Rome est une monarchie, jusqu'à ce qu'un des Rois de Rome, Tarquin le Superbe, se fasse chasser par la population par ce qu'il était trop tyranique.
Donc en 509 av J.C la république romaine est née.
Les institutions de la république ne sont qu'une évolution des institutions existantes, tel que le sénat, pour tenter d'éviter que le pouvoir absolu royale (imperium) ne soit dans les mains d'un seul tyran.
Tous les pouvoirs sont répartis entre différents magistrats qui sont chacun chargés de tâches particulières. A la tête de l'Etat, il y a 2 consuls qui ont les pouvoirs, l'imperium. Une décision n'est prise que lorsque les 2 consuls sont du même avis.
Le sénat est un conseil d'anciens, qui comme son nom l'indique est là pour conseiller les consuls.
Les citoyens romains, par l'intermédiaire d'assemblées (des comices) ont pour rôle d'élire les différents magistrats, ainsi que des censeurs.
Le rôle des censeurs est de recenser! A chaque élection de censeur, tous les 5 ans, (tous les lustres du nom de la fête de purification qui y a lieu) les censeurs font le classement des citoyens en fonction de leur âge et de leur richesses. D'après ce recensement, ils déterminent dans un livre blanc (album) la liste des sénateurs ! Généralement tout ancien magistrat est automatiquement placé dans la liste des membres du sénat.
En cas de guerre, ou de problème pour lequel on a besoin d'une prise de décision rapide. Les consuls élisent un dicatateur ainsi qu'un maître de cavalerie comme adjoint.
Le dictateur reçoit les pleins pouvoirs de l'imperium. Cependant, pour éviter d'en faire un nouveau tyran. Ces pouvoirs sont limités à 6 mois.
Voici un schéma qui résume rapidement tout le fonctionnement des institutions politique de la république romaines.
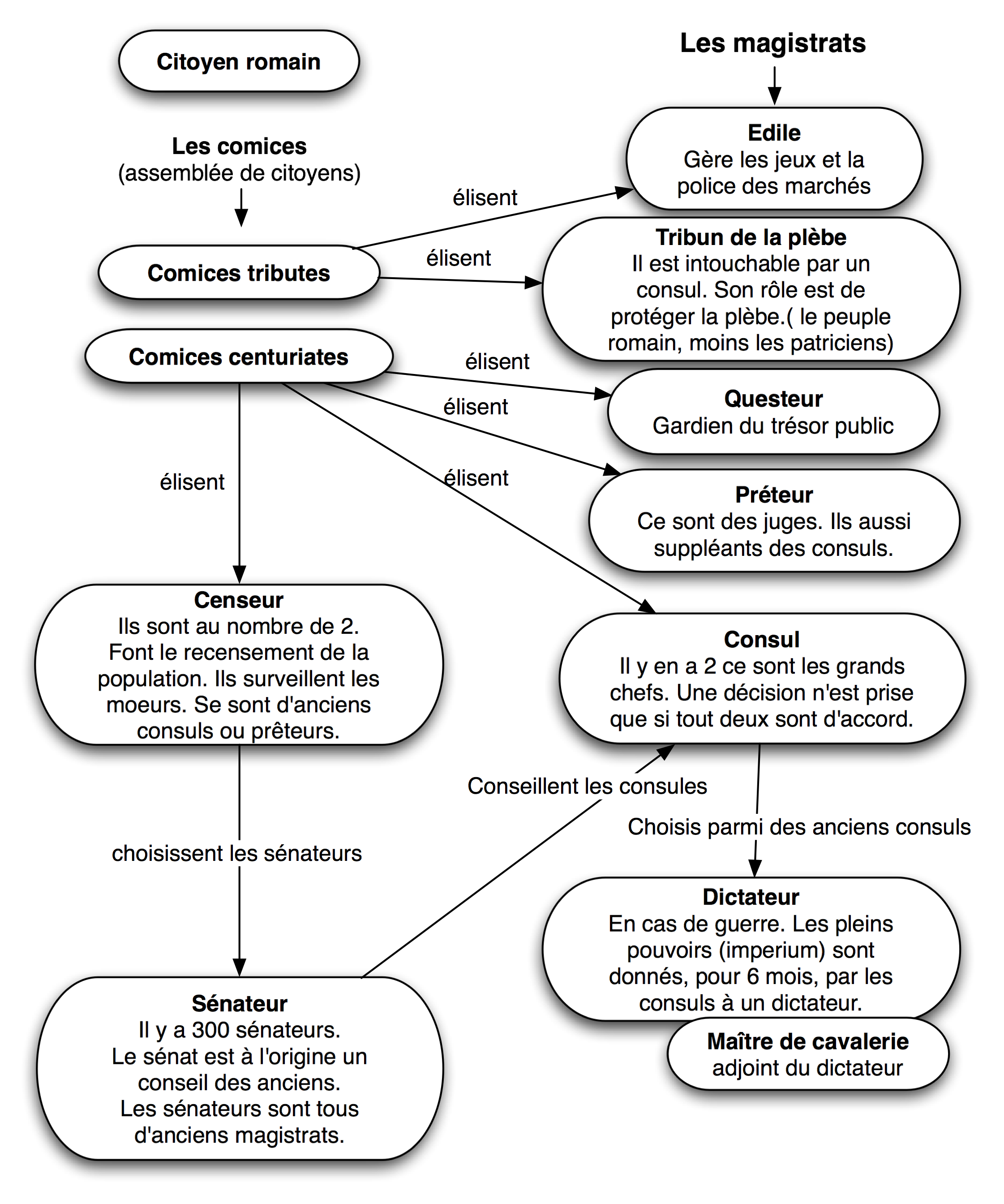
Voici le même schéma, mais au format pdf, ce qui permet un plus grande souplesse:
système_politique_de_la_république_romaine.pdf
Empire Romain
Tout ceci est bien joli, mais tout le monde sait que la république romaine est devenue un empire romain!
Cela signifie donc que les buts de la république d'éviter une tyranie n'ont pas fonctionné. Ceci est du à un accord, le triumvirat entre Jules César, Pompée et Crassius.
Jules César à réussi à se faire nommer dictateur et prolonger son mandat de 6 mois à 10 ans ! et puis de 10 ans à dictateur à vie. Ceci montre bien la fragilité du système. Il se trouve que la réaction ne s'est pas fait attendre et que Jules César à été assassiné !!!
Mais l'empire était en marche et ses successeurs se sont nommés Auguste !
La Révolution Française
Depuis des siècles en France, c'est une monarchie qui gouverne. Les rois de France prennent de plus en plus d'importance. Louix XVI se fait même déclarer Monarque absolu de droit divin. Les différences de classes deviennent de plus en plus marquées entre l'aristocratie riche et les pauvres qui deviennent de plus en plus pauvres. Les idées du siècle des lumières font leur chemin... Les Etats unis d'amérique déclarent leur indépendance et en 1789 la révolution française éclate.
Le but de cette révolution est d'abolir les privilèges de classe. Tous les citoyens naissent égaux... La déclaration de droits de l'homme est écrite.
Cependant, malgré toute cette bonne volonté, il faut créer un nouveau système fonctionnel pour éviter que tout le pays parte dans le chaos. Chaos qui finalement va quand même régner pendant quelques années. De nombreuses formes de gouvernement vont apparaîtres et disparaîtres avant qu'un système soit adopté plus durablement.
Nous aurons dans l'ordre:
- l'assemblée constituante de 1789
- l'assemblée législative
- la convention nationale
- le directoire
- le consulat
- l'empire
- la restauration
En 1789 le roi n'arrivant plus a gouverner normalement, il convoque les Etats généraux, l'assemblée des représentants de la nation. Mais ça ne va pas mieux. Les nobles et le clergé refusent de siéger avec le tiers état. C'est donc la scission. Les députés du tiers état, ainsi qu'une fraction volontaire du clergé et de la noblesse se réunissent en assemblée constituante et créent la première constitution.
La nouvelle structure politique est basée sur la séparation des pouvoirs, l'égalité et la souveraineté nationale. Le royaume est divisé en 83 départements.
Après avoir consigné par écrit les bases de la nouvelle société. Il n'existe toujours pas de système politique. Une assemblé législative est donc constituée pour assurer le gouvernement de l'Etat.
L'assemblée législative n'était aucunement représentative du peuple et ses membres même pas élu. C'était principalement les membres de la haute bourgeoisie. Cet état de fait provoqua pas mal de mécontentement, et des insurrections comme la commune de paris. (Celle de 1790 et pas celle de type anarchiste de 1870)
Suite à ces évènements, le suffrage universel à été employé pour élire les membres d'une nouvelle assemblée, la convention nationale. Cette convention assurait le législatif. Elle format un conseil exécutif formé de 6 membres pour l'exécutif et également un tribunal pour instruire le procès de Louis XVI et Marie Antoinette.
La convention a également créer plusieurs institutions importantes comme l'école normale supérieure, l'école polytechnique, l'école des arts et métiers, le conservatoire de musique, le musée d'histoire naturelle et le système métrique.
La convention nationale s'est rapidement transformée en ce que l'on appelle le directoire.
L'exécutif est assuré par 5 directeurs, qui sont élus par le conseil des anciens. Chaque année un des directeurs est tiré au sort pour être remplacé. Le corps législatif est composé de deux organes, le conseil des anciens et le conseil des 500.
Le conseils des Anciens comportait 250 membres âgés d'au moins 40 ans. Chaque année, on renouvelait un tiers du conseil. Le rôle de ce conseil est d'adopter ou de rejeter ce qui est proposé par le conseil des 500. Le second rôle de ce conseil est d'élire les directeurs.
Le conseil des 500 à pour rôle de concevoir les projets de loi et les listes de candidats pour le directoire. Puis il les transmet au conseil des anciens. Les membres du conseil des 500 sont élus au suffrage censitaire. Ce qui signifie en fonction du niveau de fortune !!!
Les directeurs sortant n'avaient pas la possibilité de se faire réélire.
Le directoire c'est très vite transformé en triumvirat corrompu. Le système a été supprimé par le coup d'état de Bonapart.
Coup d'Etat du 18 Brumaire
Je trouve toujours assez étrange que des gens qui sont les défenseurs d'une démocratie, d'une république arrivent à donner les plein pouvoirs à une personne unique. J'ai tenté un peu de comprendre comment est ce que Napoléon Bonaparte à réussi à se retrouver à la tête de l'Etat Français.
D'abords, il faut signaler que depuis la révolutions, ce sont de multiples systèmes qui se sont succédés très rapidement. On remarque bien, que personne ne sais vraiment comment il faut concevoir un système politique et que c'est par de multiples essais que l'on procède.
Le principe de la constitution de l'An III avait pour but de figer un système avec des moyens de bloquage de toutes les institutions entres elles pour éviter une prise de pouvoir par un tyran.
Emanuel Joseph Sieyès a fait partie de toutes les formes de gouvernement de l'époque, des Etats-généraux de Louis XVI au consulat avec Bonaparte. Au moment de la rédaction de la constitution de l'An III Sieyès est partisan d'un organe sensé contrôler la conformité avec la constitution des actes des organes de l'Etat. Cette proposition ne sera pas retenue.
Sieyès va alors tenter de remettre l'idée à l'ordre du jour, lors qu'il est membre du directoire. Cependant, la constitution est tellement ficelée qu'elle ne peut être modifiée avant 9 ans !!! (pas encore compris pourquoi)
Sieyès décide alors de changer de méthode et d'utiliser celle du coup d'Etat qui est, somme toute, assez courante à cette époque!
Il s'organise alors, il s'arrange pour avoir le soutien d'une partie du conseil des anciens, il s'arrange pour décider la majorité de ses collègue du directoire à démissionner et s'arrange avec le général Bonaparte pour que le conseil des anciens lui donne le commandement en chef des armées.
Un fois ce commandement reçu, Napoléon est déjà investi de pouvoirs énormes! C'est finalement là la faille. C'est une trop grande confiance en Napoléon.
Puis, avec un subtile déménagement des autorités à St-Cloud, le coup d'Etat commence. Napoléon explique qu'il est en colère et qu'il n'est pas content du travail du conseil qui a selon lui trahit plusieurs fois la constitution. Il propose de partir avec de nouvelles bases. Le députés l'acceptent mal, malgré les tentatives d'explications du frère de Napoléon, Lucien Bonaparte qui était président du conseil des anciens.
Se sentant attaqué et en danger de mort, Napoléon prend le contrôle militairement du conseil et fait évacuer la salle.
Plus tard, c'est en réunissant les membres du conseil favorable à Bonaparte que le consulat est mis en place.
La république est maintenant dirigée par 3 consuls. Napoléon devient premier consul aidé par Sieyès et Roger-Ducos.
De nouvelles institutions sont mises en place:
- le conseil d'état qui rédige les lois
- le tribunat qui discute des lois (mais ne les votes pas)
- le corps législatif qui adopte ou rejette les lois. (mais ne les discute pas)
- le Sénat qui vérifie la conformité des lois avec la constitution. (c'est ce qui ressemble le plus à l'idée d'organe de contrôle que Sieyès voulait)
Ce système est terriblement réparti pour que finalement se soit les consuls qui dirigent tout ! (et surtout le premier consul)
Napoléon empereur
Finalement le consulat est un système assez stable. Pour éviter qu'il ne s'effondre en cas d'effondrement du consulat, le Sénat propose de faire de Napoléon un Empereur !
L'idée peut paraitre étrange, mais le but est de faire de Napoléon l'incarnation des valeurs de la république. Et de transmettre de manière héréditaire ces valeurs !
Tout les symboles de monarchie sont alors recréés et toute une aristocratie, pourtant abolie quinze ans plus tôt est recréée !
Napoléon va transformer l'Europe en agrandissant son empire et en imposant les institutions de la république.
La plupart des institutions démocratiques européennes sont le fruit des idées de Napoléon. On pourra citer par exemple le code civil. (Il a aussi permis à des financiers Suisses de créer la banque de France... une banque à leur service.. et d'octroyer à cette banque le monopole d'émission des billets de banques. Ce qui a valu à Napoléon d'avoir le soutien des financiers et de rester au pouvoir....)
L'idée de faire de Napoléon l'incarnation des valeurs de la république n'était donc pas une si mauvaise idée, même si tout ne s'est pas passé par la suite comme on le pensait. Le règne de Napoléon à permis de mettre en place rapidement et durablement une multitudes de nouvelles institutions républicaines et sur un vaste territoire.
Les Etats Unis d'Amérique
Tout le système politique des Etats Unis d'Amérique est basé sur la constitution. Cette constitution est une des plus vieille du monde. Toutefois elle a quand même été amendée 27 fois.
Le but de cette constitution était d'unir des ex colonies autonomes pas toujours très stable politiquement. La constitution a permis de créer une notion démocratique d'égalité de traitement pour tout les citoyens.
Afin d'éviter une concentration de pouvoir, la constitution est conçue de manière à créer un régime politique avec des pouvoirs très séparés.
Pouvoir législatif
Le législatif est une assemblée nommée Congrès qui est bicamérale elle comporte la chambre des représentants et le sénat. Comme son nom l'indique, la chambre des représentant représente proportionnellement le peuple et est renouvellée par suffrage direct tout les 2 ans. Le sénat comporte 2 sénateurs par Etat. Le Sénat est renouvelé par tiers tous les 2 ans.
Les lois doivent être votée par les 2 chambres pour être accepté. Si le président le désire, il peut apposer son veto. Ce qui augmente le majorité (2/3) pour l'acceptation d'une loi.
Pouvoir exécutif
C'est le président qui exerce le pouvoir exécutif. Il est le grand chef des armées. Il nomme les hauts fonctionnaires et les juges fédéraux (avec l'approbation du sénat ). Le vice président, quand à lui préside le Sénat.
Pouvoir Judiciaire
Le pouvoir judiciaire est détenu par la cour suprême. Les juges de cette cour sont nommés à vie ! Les pouvoirs étant très séparé. La cour suprême est le pouvoir qui doit trancher lors des blocages entre exécutif et législatif ceci afin de ne pas bloquer trop longtemps l'appareil politique.
Election présidentielle
L'élection du président et du vice président des Etats-Unis d'Amérique est une élection avec une machinerie compliquée. C'est une élection au suffrage universel indirecte. En effet, ce sont des grands électeurs qui élisent le président et vice-président. Les citoyens votent donc pour les grands-électeurs de leur Etat. Il y a autant de grands électeurs que de membre du congrès pour leur Etat.
Les citoyens votent donc pour un grand électeur qui annonce qu'il va voter pour un candidat. (Il n'est pas obligé de le faire, mais c'est le cas dans l'immense majorité des cas.)
Puis, les grands-électeurs votent pour un candidat et on fait le décompte. Pour chaque Etat, c'est le candidat qui obtient la majorité des grands électeurs qui emporte le vote dans l'Etat. Dans tous les Etats (sauf 2), le candidat qui emporte le vote gagne les voies de TOUS les grands électeurs de l'Etat. (Toutes les voies des grands électeurs de l'Etat sont identiques!). Pour finir on fait le compte des grands électeurs sur le pays entier. Le candidat qui obtient la majorité absolue des grands électeurs gagne l'élection. Si aucun candidat n'obtient de majorité absolue, c'est la Chambre des représentants qui élit le président, et le Sénat qui désigne le vice-président.
A toute cette machinerie électorale s'ajoute encore la désignation des candidats par les partis politiques. Officiellement pour être candidat il faut, (ne pas avoir été déjà 2 fois président !) être citoyen Etat-unien né sur le territoire, âgé d'au moins 35 ans et candidat dans les 50 Etats de l'Union.
Pour être candidats dans les différents Etats, il y a différentes règles. Mais en général, c'est obtenir un certain nombre de signature de parrainage.
Puis, après les démarches officielles, pour être candidat, il est mieux d'avoir le soutiens (populaire et financier) d'un parti. (Républicain ou démocrate c'est mieux !)
Les partis ont des processus compliqués de désignation de candidats. Dans chaque Etat la procédure change. En général, il s'agit de vote populaire (mais rarement plus de 10% de la population!) accessible à toute la population ou seulement aux membres du parti. Une seule voie par personne est autorisée.
Comme les désignations n'ont pas lieu en même temps partout, l'attention portée par les médias à une désignation (caucus) n'est pas la même. En effet, les candidats qui obtiennent de mauvais scores se retirent rapidement pour raison financière. Il ne sert à rien de gaspiller son argent en continuant.
La tendance est au regroupement de la date de désignation des candidats. En été les convention de parti désignent leur candidats officiel qui obtiennent ainsi un financement du parti.
On remarque ainsi que d'être élu à la présidence des Etats-unis est un parcours du combattant! (une expérience pour devenir le futur chef des armées !) Il faut avoir beaucoup de temps, et beaucoup d'argent. Il faut environ 1 année pour créer des comités et des alliances qui soutiendront sa candidature, puis 6 mois de campagne dans un maximum d'Etat pour être élu candidats officiel d'un parti, ce qui permettra de financer la campagne sans utiliser sa propre fortune. Puis, il faut remplir les formalités administratives pour être candidat (trouver des parrains dans tous les Etats). Enfin, il faut convaincre tout le monde de voter pour soi!
Star wars
C'est en étudiant le système politique de la république romaine que le film star wars m'est revenu à l'esprit. Je trouve qu'il y a beaucoup de similitudes.
La galaxie est une république formée de plusieurs mondes. Un de personnage est la princesse Amidala qui est une princesse élue. On la suit lors d'une séance au parlement, durant laquelle, le Sénateur Palpatine reçoit les pleins pouvoir. C'est le principe de la dictature de la république romaine, et tel Jules César ou Napoléon Bonaparte, Palpatine devient Consul à vie puis Empereur !
Suisse
La Suisse est une démocratie semi-directe. Le peuple entier à toujours le dernier mot s'il le faut.
Mythe fondateur Suisse
Le système politique suisse est à la base une confédération de régions souveraines qui refusaient l'ingérence des Habsbourg et de leur fonctionnaires dans leur vie quotidienne. De plus le péage du Gothard rapportait un bon pécule qui attire les convoitises.
Les gens de ces vallées ayant défié leur suzerain, ils devaient s'attendre à des représailles militaires. La confédération a donc été crée lors du serment du Grütli. C'est un pacte qui prévois assistance entre 3 vallées en cas d'agression.

Les représailles sont venues. Le Duc Léopold 1er d'Autriche a envoyé des milliers de soldats qui ont été défait à la bataille de Morgarten par des paysans/soldats 2 fois inférieurs en nombre.
Après cet évènement, la confédération a grandi, ce qui n'était pas bien vu du saint empire romain germanique. C'est ainsi donc que 73 ans après Morgarten, c'est à Sempach que les hostilités ont reprises. Et suivant le même modèle, les confédérés ont remporté la victoire. Leopold III perdant la bataille et la vie! (comme 15% de la noblesse alsacienne)
Depuis, la confédération suisse vit tranquillement. La confédération est devenue une fédération (tout en gardant le nom confédération) de canton.
Voilà pour la fable..
Remise en cause du mythe fondateur Suisse
Comme tous les mythes, celui de la suisse est inspiré de faits réels, mais romancé.
Il semble bien que le fameux pacte de 1291 est un faux ! (j'ai découvert ceci en allant le voir au musée des chartes à Schwytz.)
En très bref, ce pacte présente plein de signe qui montrent qu'il n'est pas fait de manière conforme à l'époque:
- le rédacteur est inconnu ! (peu de gens écrivaient les actes officiels)
- la date est floue.... (au début août..... C'est pourquoi on fête le 1er août la fête nationale)
- le pacte ne cite pas de document précédent précis (juste un vague.... "comme les anciens document le montrent")
- le sceau de Unterwaldest utilisé, alors qu'il n'existait pas en 1291... il n'y avait que des sceaux séparés pour les entités de obwald et niedwald.
- Ce pacte n'existe qu'en un seul exemplaire. (peut être que les autres ont été perdu... mais c'est louche)
- Ce pacte n'est cité par aucun autre document plus récent jusqu'en 1891 où il est utilisé pour construire le mythe suisse (et ainsi fêter les 600 ans à cette date !) ! Avant 1891 on considérait que le pacte de Brunnen de 1315 était le véritable acte fondateur de la suisse.. (Suite à la bataille de Morgarten)
(Le pacte de 1291 a été découvert par hasard dans les archives de Schwytz en 1724...)

Etonnamment, seul le musée des chartes à Schwyz, sorte de coffre fort géant construit dans les années 1930 à la gloire de ce pacte de 1291, indique et explique pourquoi ce pacte est probablement un faux !
Le site web officiel de la confédération, ainsi que la page wikipedia du pacte n'indiquent en rien que ce pacte est un faux ! C'est certainement encore un tabou...
(Tout comme le fait que Guillaume Tell n'est pas un personnage historique.... et pire.... L'histoire est identique à celle plus vieille qu'on trouve dans une fable danoise.... Toko l'archer obligé de tirer une flèche dans une pomme sur la tête de son fils.... )
D'où vient ce pacte de 1291 ?
Le musée des chartes nous indique que le pacte de 1291 daterai de 1307, et serait une sorte de pièce jointe au CV d'un bailli qui voulait justifier d'une certaine indépendance historique de la région aux yeux du nouvel empereur du Saint-Empire Romain-Germanique.
Il aurait donc créé un faux pacte et l'a anti-daté histoire de justifier une continuité historique d'indépendance du lieu de tout intermédiaire entre le bailli et l'empereur. (alors qu'en général, il y avait toujours une famille noble en intermédiaire !)
Ça semble avoir fonctionné. En 1309, l'immédiateté impériale a été accordée par l'empereur Henri VII de Luxembourg. Donc une certaine autonomie, bien plus qu'ailleurs.
Je trouve cette histoire très intéressante, je ne vois pas pourquoi elle devrait être tabou ?
Les batailles de Morgarten et Sempach on réellement existées.
Il y a réellement eux plein d'autres pactes similaires à celui de 1291 qui ont véritablement créés la confédération helvétique.
En fait, c'est les idées nationalistes de la fin du 19ème siècle, puis les périls fascistes et communistes des années 1930 qui ont impulsé la création d'un mythe suisse. (et la construction du musée des chartes à Schwyz)
Qu'est-ce qui fait que la suisse est ce qu'elle est ?
C'est un pays qui n'est pas vraiment une nation homogène. Car il y a plusieurs langues, plusieurs religions et une grande diversité culturelle.
=> La réponses saute aux yeux. La particularité de la Suisse c'est de mettre ensemble ce qui a priori ne va pas ensemble.
Le pacte de 1291 est l'emblème de cette idée. Il raconte l'histoire de 3 vallées qui se mettent ensemble.
"Unus pro omnibus, omnes pro uno", un pour tous, tous pour un, est la devise de la Suisse.
Donc le mythe crée un égrégore qui devient une prophétie auto-réalisatrice. La suisse est bien un lieu où l'on arrive à mettre ensemble ce qui ne va pas ensemble à priori.
L'épisode politique de la république helvétique le montre bien.
Donc peu importe si le pacte de 1291 est vrai ou faux, les idées qu'il véhicule sont bien vivantes en Suisse !
La république Helevétique
Après les batailles de Morgarten et Sempach qui garantissent une certaine autonomie à la confédération des canton suisse. La confédération s'étend et colonise des territoires. Les cantons administrent des baillages communs. Il y a des cantons qui sont plus fort que d'autres. On peut notamment dire que le pays de vaud est une colonie du canton de Berne.
Puis Napoléon est arrivé. Il a conquis la Suisse en 1798 pour créer la république Helvétique sur le modèle de la république Française.
- Un législatif à deux chambres
- Un exécutif, le directoire
- Une cours de justice supérieure
L'innovation a également ét de rendre tous les cantons égaux. Fini les baillages et les colonies.
Mais voilà... on ne gouverne pas la Suisse multiculturelle ainsi ! Comme dit plus haut le propre de la Suisse c'est de mettre ensemble ce qui ne va pas ensemble. Napoléon a bien du s'y résoudre.
En 1803 la république Helvétique c'est fini, place à l'acte de médiation.
Napoléon dira:
« La Suisse ne ressemble à aucun autre État, soit par les événements qui s'y sont succédé depuis plusieurs siècles, soit par la situation géographique, soit par les différentes langues, les différentes religions, et cette extrême différence de mœurs qui existe entre ses différentes parties. La nature a fait votre État fédératif, vouloir la vaincre n'est pas d'un homme sage. »
« Ce qui est en même temps le désir, l'intérêt de votre nation et des vastes États qui vous entourent est donc :
- 1° l'égalité des droits entre vos dix-huit cantons
- 2° une renonciation sincère et volontaire aux privilèges de la part des classes patriciennes
- 3° une organisation fédérative, où chaque canton se trouve organisé suivant sa langue, sa religion, ses mœurs, son intérêt, son opinion. »
Donc voici une transition d'un Etat centralisé à un état fédéral qui est plus proche de l'habitude confédéral des Suisse. Ce qui permet de faire vivre ensemble ce qui à priori ne va pas ensemble.
Napoléon reste quand même à la tête de la politique Suisse. Surtout de la politique étrangère. Histoire de mener à bien ses idées sur le monde.
A la chute de napoléon et son empire. La Suisse s'émancipe vraiment et lors du congrès de Vienne, (Cette réunion d'une bande de potes qui refont le monde !) la Suisse devient officiellement Neutre.
C'est le système de la confédération des 22 cantons.
De la réforme de Napoléon à l'Etat fédéral Suisse moderne
Le parti radical démocratique prend de l'ampleur dans des cantons surtout urbains et protestants. Ils font passer des mesures anti-catholiques. Les cantons catholiques prennent peur et font une alliance secrète: le sonderbund. Ils cherchent à se faire protéger par l'autriche, ce qui est contraire à la constitution.
C'est la guerre du Sonderbund qui éclate. Elle est très courte, trois semaines, et voit la défaite des catholiques.
A cette occasion une nouvelle constitution est adoptée, qui voit la création d'un véritable état fédéral. C'est la fin de la confédération, même si le nom est resté !
Les cantons sont souverains, mais délègues des compétences à la (con-)fédération. C'est ce que l'on appelle la suisse moderne de 1848 dont le système est toujours en vigueur.
Système politique Suisse depuis 1848
Le système politique suisse dispose de 3 niveaux. Les communes, les cantons et la confédération. Chaque niveau est responsable de ses compétences, selon le principe de subsidiarité.
Comme législatif, la confédération a un parlement, l'assemblée fédérale, qui est divisée en 2 conseils. Le conseil des états où siègent 2 représentants par canton. Et le conseil national ou siègent des représentants de la population, chaque canton ayant un nombre proportionnel à sa population de représentants.
Ces conseils discutent et adoptent les lois, proposées par les différentes commissions qui les ont préparées. Pour qu'une loi soit acceptée elle doit être adoptée par les 2 conseils.
L'exécutif, quant à lui est le conseil fédéral. Ce conseil est élu par l'assemblée fédérale. Chaque année, la présidence de l'Etat change en fonction d'un tournus entre les membres du conseil fédéral. (formellement élu par l'assemblée fédérale)
Le peuple à toujours le dernier mot, par ce qu'en plus d'élire ses représentants, il a un droit de référendum sur toutes les décisions du parlement.
De plus, depuis 1891, il a aussi un droit d'initiative pour proposer de nouveaux articles constitutionnels (par pour de nouvelles lois). Pour qu'une initiative ou une modification de la constitution soit possible, il faut que la majorité des cantons et la majorité de la population l'accepte. (double majorité)
J'ai découvert récemment (en 2018) qu'en l'absence d'un organe qui vérifie la conformité d'une nouvelle loi par rapport à la constitution, c'est le peuple qui est chargé de faire cette vérification. Si une loi n'est pas combattue par référendum au moment de sa création par le parlement. Alors elle est considérée comme acceptée et prime sur la constitution, même si elle est contraire à la constitution !!
(C'est ce que j'ai découvert avec la Loi sur la Banque Nationale Suisse qui est légèrement différente de la Constitution dans ses possibilités de redistribuer le bénéfice de la BNS... ainsi au lieu de se faire distribuer directement des milliards de bénéfice, on se les fait distribuer au compte goutte, au bon vouloir de quelques technocrates....)
La démocratie uniquement bonne a garder le troupeau
La démocratie est un bon système pour maintenir des institutions en place, gérer les affaires courantes et apporter de menues adaptations au système. Mais ce n'est pas un bon système pour faire une réforme de fond en comble.
Déjà du temps de la république romaine on avait du résoudre ce problème. Sylla est devenu dictateur dans le but de faire une réforme en profondeur des institutions.
Mais on voit que donner les pleins pouvoirs à une seule personne... c'est dangereux.... Jules César, Napoléon, Plapatine....
De plus, il y a plein d'article constitutionnel qui ne sont pas respectés. Donc, à mon avis, un texte ne garantir pas grand chose. C'est surtout quand il y a une volonté populaire exprimée par un texte que le texte fonctionne. Tout dépend des visions du monde des gens pour savoir comment ils sont prêt à accepter l'existence d'un texte. Est-ce que c'est le texte qui fait foi fondamentalement ? est-ce que le texte est juste là pour être un cadre à contourner ? est-ce que c'est l'esprit derrière le texte qu'il faut respecter ?
Là on voit les limites du texte, et donc l'influence d'autres pouvoirs devient plus importante. Au cours de l'histoire on voit, notamment avec Napoléon, que le pouvoir militaire n'est pas négligeable. A notre époque, j'ai l'impression que c'est le pouvoir économique qui est le plus influent. Ce dernier fonctionne conjointement avec les pouvoirs monétaire et médiatiques. (banques et médias qui appartiennent aux grands groupes et aux banques...)
La volonté populaire est parfois capable de faire des retournements de situations avec des "révolutions", mais très souvent ces révolutions ne font que changer les têtes et pas le système. (C'est bien ce que le mot révolution signifie... retourner à la même place... comme la révolution des planètes autour du soleil)
Les révolutions arabes de 2011, ont largement été récupérées.... la révolution russe de février 1917 a libéré des opposants politiques qui sont venus créer la révolution d'octobre....
Quand on regarde derrière les révolutions colorées des années 2000 en europe on voit qu'elles sont toutes financées par des ONG façade de la CIA.... (Par exemple l'ex directeur de la CIA était le président de Freedom House à cette période) Voir à ce propos mon article sur les BRICS qui reconstruisent le monde...
Un changement de système est toujours chaotique... et généralement c'est la loi du plut fort qui s'impose.... donc certains aiment bien profiter du flou chaotique....
Monarchie
La monarchie est un des systèmes les plus anciens et le plus simple. Il y a un chef et à sa mort, ce sont ses descendants qui le remplacent.
La monarchie est présente sous beaucoup de formes différentes. Et souvent, il y a toute une noblesse qui est crée autour.
C'est en général, un système qui est basé sur des accords individuels de soutient entre des monarques. La notion de vassal et de suzerain est très présente.
Dans la noblesse il y a des titres, mais il ne sont pas normalisés il ne sont pas forcément représentatifs. C'est surtout les alliances qui forment le pouvoir de l'un ou l'autre monarque.
Dans l'europe du moyen âge, les titres de noblesse sont souvent issus des institutions de l'empire romain.
Le Duc, n'est que la transformation du Dux, qui était, à l'origine un terme romain (mais pas un grade) pour désigner un commandeur, un chef des armées. Puis, plus tard durant l'empire romain, les Duces sont devenus des chefs des certaines parties frontières de l'empire. Il y avait 12 duchés dans l'empire d'orient et 13 dans celui d'occident. Le pouvoir de ces Ducs étaient presque total. Il étaient chef de l'administration, de l'armée et de la justice.
Lorsque l'empire romain est tombé, cela à permis à plusieurs Ducs de se libérer et de devenir autonome. Certains duchés ont également été repris par des seigneurs barbares.
Ensuite, la répartition des titres c'est faite souvent de manière géographique. Les premiers souverains du moyen âge distribuaient les responsabilités de morceaux de territoire à leur compagnons, des comtes. En effet, Comte est un mot qui vient du latin comes qui signifie compagnons. C'est ainsi que sont apparus les comtés.
Le terme de roi, vient du latin rex, tireur de trait, ceci provenant de l'histoire de Romulus qui marqua à la charrue les limites de Rome. Un roi étant le suzerain de plusieurs comtes, c'est lui qui détient le commandement militaire sur tous les comtés.
Ceci à une exception, les comtés qui se trouvent en frontière (sur les marches) du royaume ont le droit de lever une armée sans en référer au souverain dans le but de l'utiliser pour défendre les frontières du royaume. Le comte qui est le chef d'un tel comté reçoit donc le titre de marquis (qui signifie comte de marche) et ceci pour marquer cette liberté militaire.
Le reste des titres de noblesse comme le vicomte ou le baron ne sont que des titre pour marquer une certain hiérarchie qui est très dépendante d'alliances.
Grèce antique
En grèce antique on trouve des systèmes politiques de plus étranges dont on est plus du tout habitués !
C'est également le berceau de la démocratie. Il faut que je me replonge dans l'histoire pour mieux saisir ce que signifie tout les systèmes mis en place.
Archonte
Après la mort du roi Codros au XIème siècle av J.-C Athène cesse d'être une monarchie. On remplace le roi par un Archonte. Au début l'archonte est élu à vie, ce qui, hormis l'hérédité de la charge, ne change pas grand chose. Puis on réduit la durée du mandat à 10 ans et on place non plus un, mais trois archontes. Puis le mandat est encore réduit à une année.
Les archontes sont élus dans l'aristocratie. Aristocratie qui est aussi un système politique ! C'est le gouvernement par les meilleurs. (la révolution française à semé la confusion entre aristocratie et noblesse. Le mérite ou la naissance.)
Dans les archontes on trouve:
- l'archonte eponyme. C'est le chef de l'Etat, on donne son nom à l'année. En charge de l'administration civile, tuteur des veuves et orphelins.
- l'archonte roi. Il est en charge de la justice.
- le polémarque. Il est à l'origine chef des armées, avant que ce ne soit les stratèges qui reprennent le rôle au moment de l'instauration du système stochocrate.
Depuis 487 av J.-C l'élection aux magistratures ont été faite par stochocratie... par tirage au sort ! Qui est la seule technique pour garantir une vraie démocratie. (au contraire de l'aristocratie)
Puis, six thesmothètes ont été ajoutés pour assurer principalement de fonction de justice.
Tyrannie
Il semble que le système des archontes est sensible au coups d'états. Il est arrivé quelques fois qu'un tyran prenne le pouvoir. Un tyran est un personnage très populaire, du moins au début de son règne, qui prend le pouvoir grâce au peuple.
Démocratie
Après une ère de tyrannie, très dure par Hippias et son frère Hipparque est assassiné et Hippias chassé en 510 av J.-C. La démocratie apparait.
Le tyran a été chassé par un groupe d'aristocrate parmi lesquels on trouvait Clisthène. C'est lui qui va ensuite réformer les institutions archaïque pour les rendre démocratiques et ainsi marquer l'entrée dans l'époque classique.
C'est la révolution isonomique.
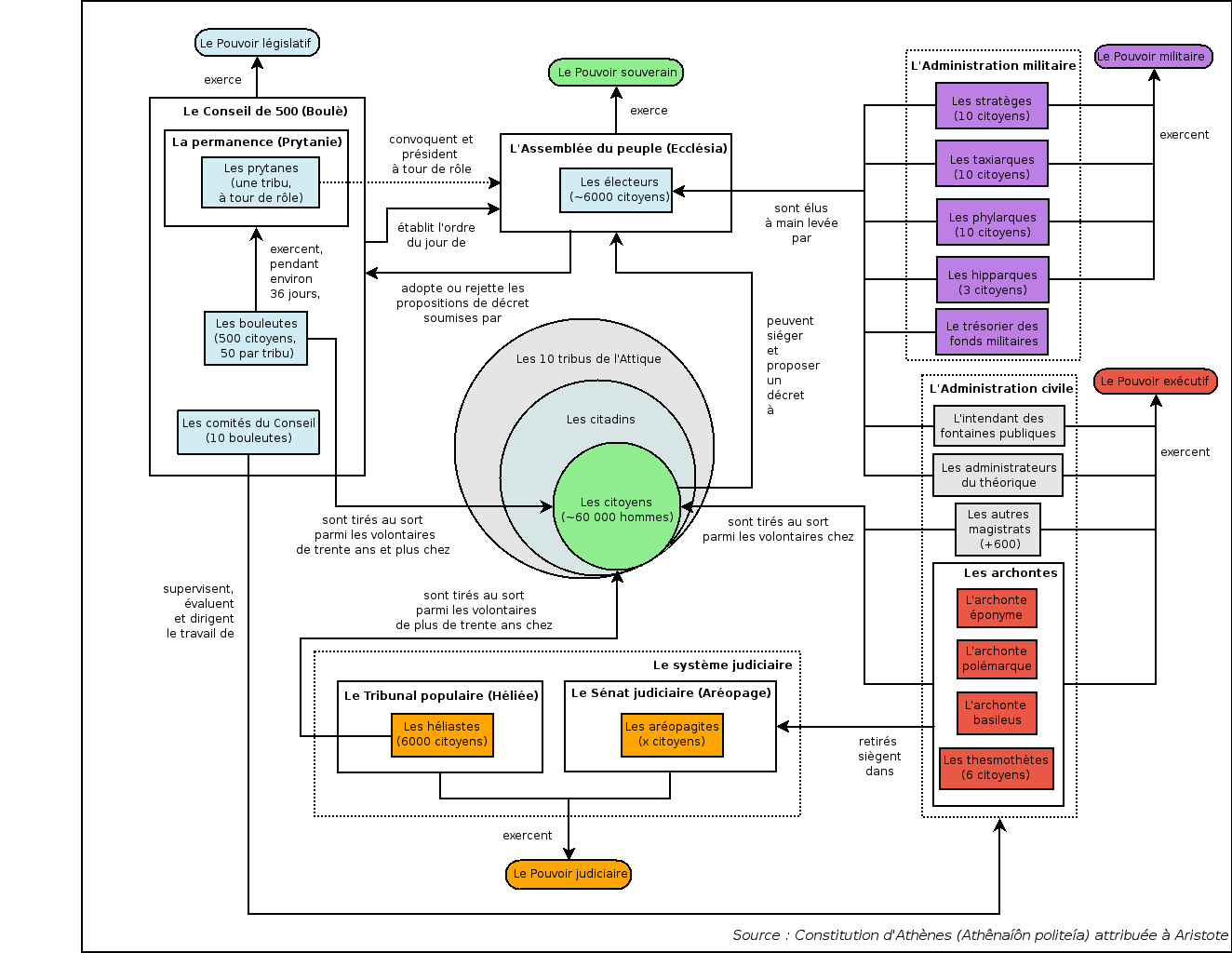
Historiquement, dans le monde archaïque, c'est l'aéropage qui est le conseil qui a le plus de poids. L'aéropage est un conseil qui historiquement est composé de nobles, de gens biens nés. Ensuite, après les réformes du légiste Solon, l'aéropage est constitué des anciens archontes. Et ceci à vie.
Clisthène va tenter de déplacer le pouvoir dans l'ekklêsia. L'assemblée du peuple. Tous les Athéniens mâles de plus de 18 ans ont le droit de participer à l'Ekklêsia. Cela représentait potentiellement environ 40 000 personnes, cependant jamais plus de 6000 personnes venaient.
Le rôle de l'ekklêsia était de décider des lois, et également de pratiquer le vote d'ostracisme. Le vote d'ostracisme permettait de désigner la personne la plus dangereuse pour l'Etat. Cette personne était exilée de la cité pour 10ans ! L'ekklêsia se réunis plusieurs fois par mois. (1-4, il y a 10 mois dans l'année politique)
L'Ekklêsia est l'assemblée du peuple au complet, l'aréopage, l'assemblée des anciens archontes, et la boulé devient une assemblée représentative du peuple. Clisthène a créé dix tribus pour les athéniens avec chacune un héro et des cultes. Chaque tribu est représentée à la boulé par 50 prytanes.
L'année politique Athénienne est divisée en 10, une part, par tribu. Chaque tribu est responsable d'une de ces parties. Les prytanes de la tribu responsables sont logés directement à proximité du Bouleutérion.
Le choix des prytanes se fait par une élection des candidats, qui sont âgés d'au minimum 30 ans. Puis, 50 des candidats sont tirés au sort.
Chaque jour il y a un nouveau superviseur des prytanes qui est tiré au sort, un Epistate. C'est en quelque sorte le chef de l'Etat. Il ne peut être Epistate qu'une seule fois. Il est le responsable de la conformités des lois qui sont votées sous son mandat.
Le rôle de la boulé est principalement de préparer les lois (faire des probouleumata) et de les soumettre à l'Ekklesia. La boulé est aussi joue aussi le rôle d'administration générale qui prépare les assemblées, et garde le feu sacré. (Chez les romains ce sera le rôles des vestales de garder le feu sacré)
Ce système politique est donc assez étrange, il est presque double. Il y a des représentants du peuple, mais il ne supprime pas les anciennes institutions donc il est accepté par l'aristocratie.
L'Ekklêsia et la boulé sont des institutions du peuple, mais les archontes, (au nombre de 10) sont des magistratures qui sont données à l'aristocratie.
Voici une représentation graphique du système politique d'Athène d'après la constitution d'Aristote. Ce schéma provient de wikipedia.
Différents types de démocraties actuelles
La démocratie est une forme de gouvernement qui a son origine dans la Grèce antique, et c'est actuellement la forme de gouvernement qui semble être la meilleure, celle qui assure le plus la stabilité de la paix.
Cependant, quand on parle de démocratie, ça ne veut pas toujours dire la même chose. Il existe de nombreux systèmes politiques démocratiques différents.
Il existe tout de même des bases fondamentales communes à toute démocratie.
- La séparation des pouvoirs exécutif, législatif et judiciaire.
- chaque citoyen a le droit de faire partie des membres du gouvernement.
Ensuite, il y a des variantes qui font qu'une démocratie est directe, semi-directe ou représentative. En effet, suivant les systèmes, et suivant la tâche, le peuple décide directement, ou désigne des représentants qui vont décider. On parle de démocratie semi-directe dans le cas où un groupe d'élu gouverne, décide, mais si le peuple n'est pas d'accord, il peut exercer un droit de référendum.
Ce que l'on appelle de nos jours démocratie n'en est pas une...
C'est là que l'on peut se poser la question: jusqu'où un système représentatif est une démocratie ?
Sieyès, dont nous avons parlé plus haut, celui qui a réussi à être à la tête de tous les différents systèmes politiques à la suite de la révolution française disait à propos de la démocratie:
« Les citoyens qui se nomment des représentants renoncent et doivent renoncer à faire eux-mêmes la loi ; ils n’ont pas de volonté particulière à imposer. S’ils dictaient des volontés, la France ne serait plus cet État représentatif ; ce serait un État démocratique. Le peuple, je le répète, dans un pays qui n’est pas une démocratie (et la France ne saurait l’être), le peuple ne peut parler, ne peut agir que par ses représentants. » (Discours du 7 septembre 1789, intitulé préciséement : « Dire de l’abbé Sieyes, sur la question du veto royal : à la séance du 7 septembre 1789 » cf. pages 15, 19…)
Ainsi selon un des principaux père fondateur de ce que l'on appelle de nos jour la démocratie moderne..... était tout à fait opposé à la démocratie dans son sens d'origine. Le système démocratique athénien, dans lequel le peuple exerçait sans représentants. Dans lequels le tirage au sort avait beaucoup d'importance.
Et si on remettait un peu de tirage au sort dans la politique actuelle ?
Bon... alors qu'est-ce qu'il y a comme type de "pseudo démocratie" ?
Régime Présidentiel
Ce qui caractérise un régime présidentiel, c'est la volonté de séparer à tous pris les pouvoirs. C'est le système le plus courant sur le continent Américain. (pas le canada)
Il est caractérisé par:
- l'exécutif et le législatif sont élus totalement séparément.
- l'exécutif ne peut pas dissoudre le parlement et réciproquement, le parlement ne peut pas renverser le gouvernement.
Régime Parlementaire
Ce qui caractérise un régime parlementaire, c'est une volonté d'avancer et d'éviter les blocages du au système politique. C'est le système démocratique qui est le plus courant en Europe.
Il est caractérisé par:
- l'exécutif et le législatif sont issu des mêmes force politique. L'exécutif est le reflet de la majorité parlementaire.
- l'exécutif et le législatif ont un pouvoir équilibré. Le législatif peut renverser le gouvernement et l'exécutif peut dissoudre le parlement.
Direction d'entreprise
Le monde politique est une chose, mais il ne décide pas de tout. Pour tous les problèmes de la vie courantes, les entreprises concernent souvent plus directement la vie des gens. Il est donc aussi très intéressant d'étudier comment sont gouvernées, dirigées les entreprises.
De plus, on remarque, que les grandes entreprises deviennent de plus en plus grandes. Que certaines emploient (et donc concernent) énormément de personnes. Au point que finalement certaines entreprises ont plus d'employés et de budget que certains Etats.
Actionnariat
= Aristocratie censitaire !
Coopérative
= 1 personne 1 voix au vote. => démocratie
Gouvernance d'entreprise et vision du monde
Le mode de gouvernance d'une organisation, d'une entreprises dépend surtout de la vision du monde de son dirigeant (fondateur)
=> Il y a aussi plein d'autres formes de gouvernances qui émergent. A lire notamment le livre de Frédéric Laloux: Reinventing Organizations, dont voici mon résumé...
Pour la suite....
Voici encore quelques pistes à étudier:









